The SoloWay team successfully uses object detection technology for various projects to automate and optimize business operations. For example, we use object detection to detect goods in warehouses and stores, which allows our clients to optimize logistics and inventory processes. We also successfully use this technology to help businesses identify faulty parts in production and automate quality control. Our experience in developing object detection technologies allows creating solutions of any complexity.
This article discusses examples of industries where object detection can be used and how Google Lens works. We will also discuss examples of image recognition apps and how to develop an image recognition app.
Key points
What is object detection?
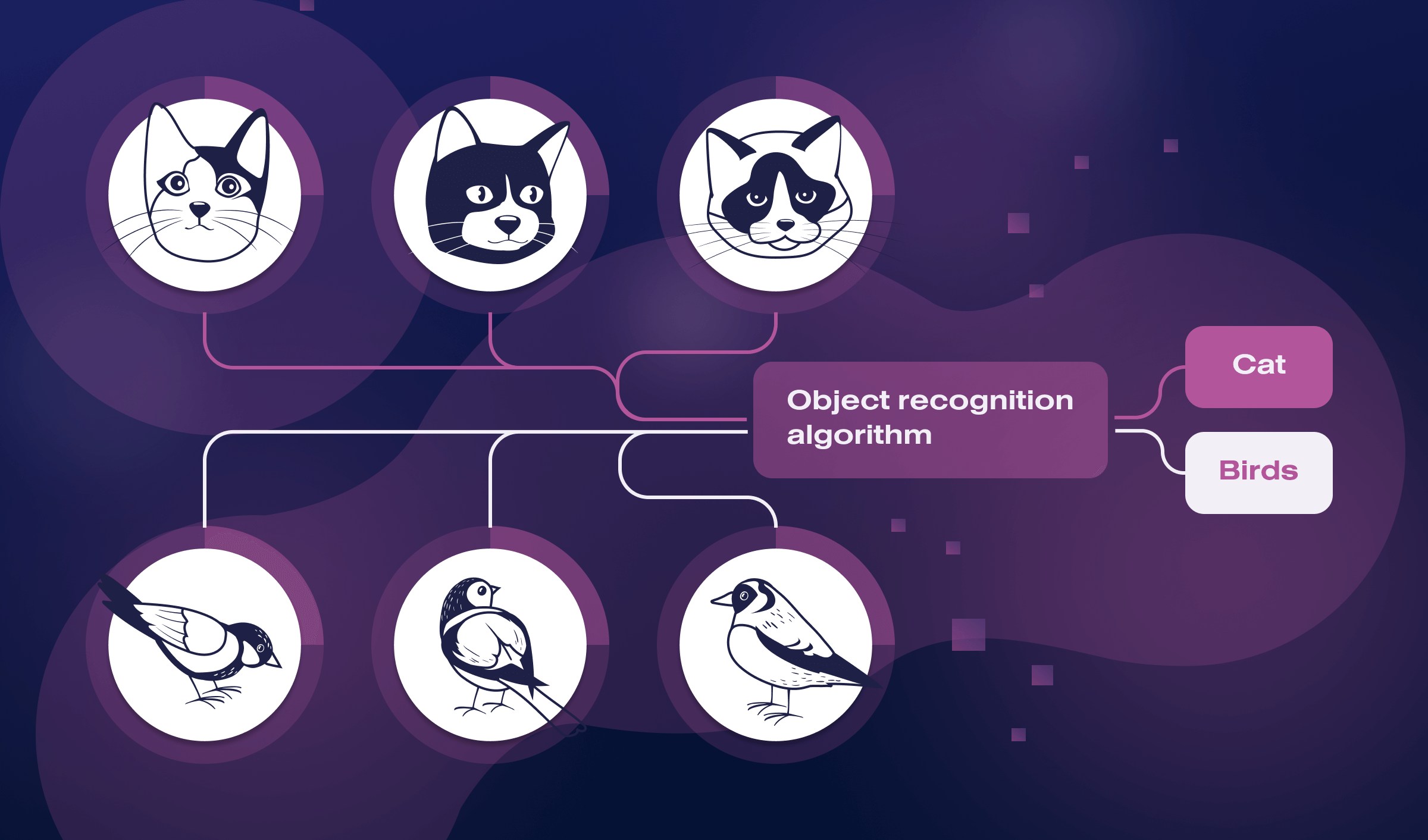
Object detection is a computer vision technology that detects and identifies objects of interest within an image or video. It is a crucial task in various fields, such as autonomous driving, surveillance, and robotics, where machines must identify and track objects in real-time.
Object detection algorithms typically work by first detecting regions in an image that may contain objects using a technique called object proposal. These regions are then analyzed using machine learning algorithms, such as convolutional neural networks (CNNs), to determine the presence of objects and classify them into predefined categories, such as humans, cars, or animals.
The output of an object detection system usually includes the location of detected objects, represented as bounding boxes and their corresponding labels. Object detection can be performed using various approaches, including two-stage methods like R-CNN and one-stage methods like YOLO and SSD.
Examples of industries where object detection can be used
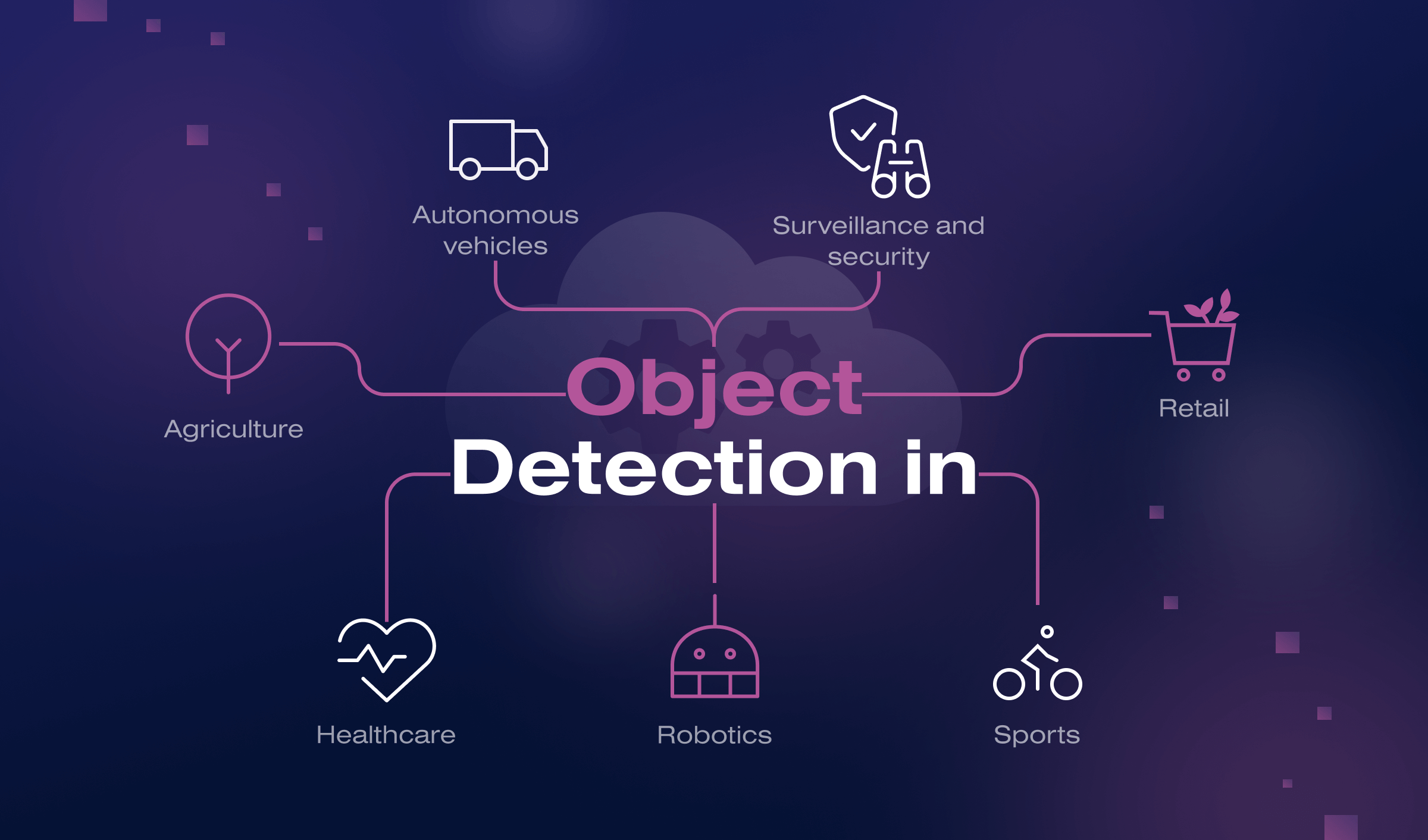
Object detection technology has many practical applications across different industries:
- Autonomous vehicles. Object detection is used extensively in developing autonomous vehicles, which must identify and track objects such as pedestrians, other vehicles, and road signs.
- Surveillance and security. This technology identifies and tracks objects of interest in security cameras and surveillance systems, such as people, vehicles, and suspicious objects.
- Retail. Object detection helps to monitor foot traffic, detect shopper behavior, and track inventory levels in retail stores.
- Agriculture. Agriculture companies worldwide use it to identify and monitor crop health, detect pests and diseases, and track livestock.
- Healthcare. This cutting-edge technology can be used in medical imaging to identify and locate abnormalities, such as tumors, in X-rays, CT scans, and MRIs.
- Robotics. Object detection can enable robots to identify and manipulate objects in real-world environments, such as manufacturing plants or warehouses.
- Sports. Object detection technology can track athletes’ movements, detect rule violations, and analyze game statistics in various sports, such as basketball and soccer.
Our developers have extensive experience in applying object detection technology for different purposes. This allows us to implement object detection solutions in almost any business domain.
Object detection algorithms
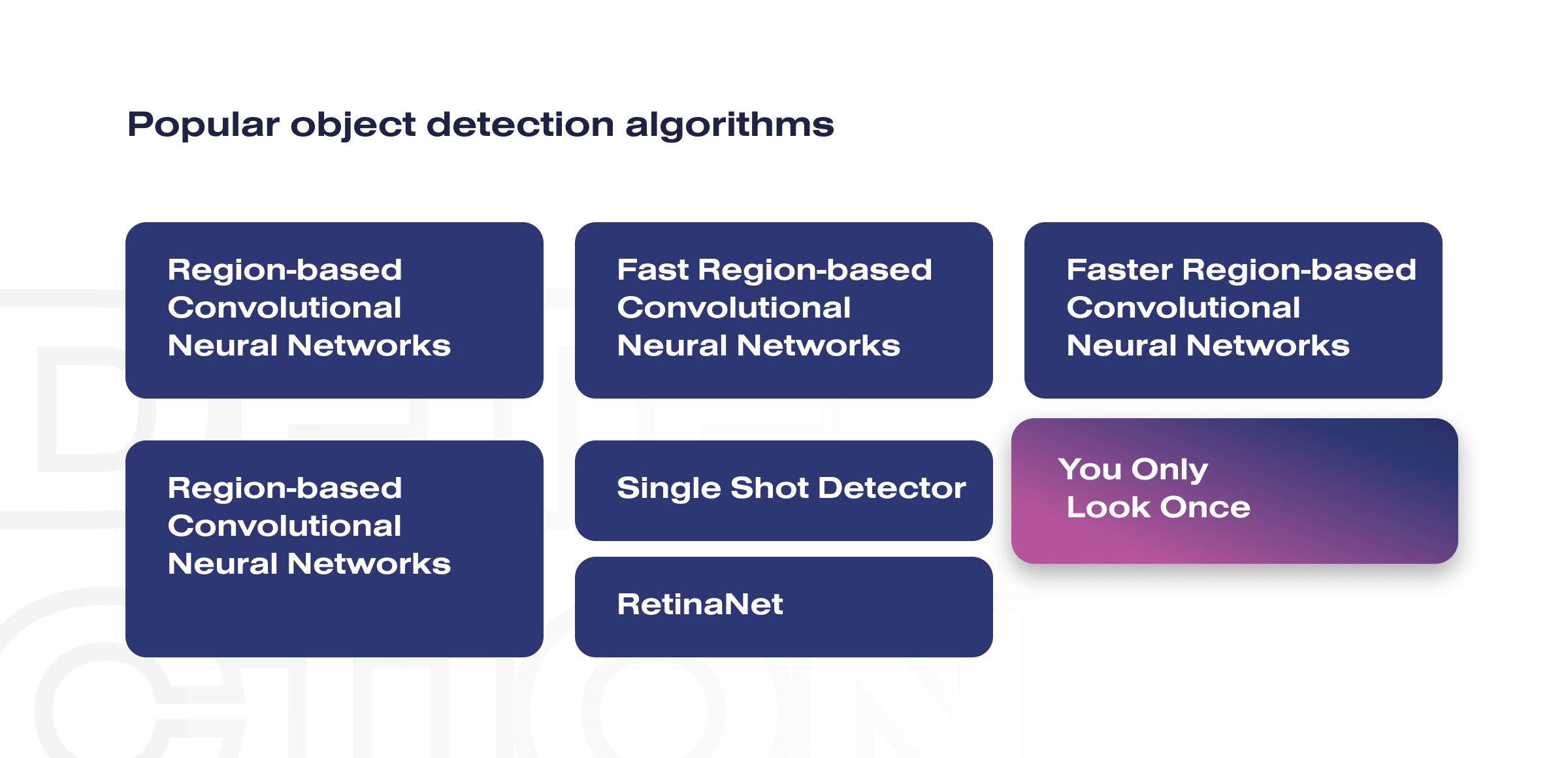
There are several object detection algorithms, each with different strengths and weaknesses:
- Region-based Convolutional Neural Networks (R-CNNs). This object detection algorithm uses selective search to propose regions of interest fed into a CNN to extract features and classify objects.
- Fast R-CNN. Fast R-CNN improves on R-CNN by sharing computation between the region proposal and classification stages, resulting in shorter processing times.
- Faster R-CNN. This object detection algorithm introduces a Region Proposal Network (RPN) that shares features with the object detection network, resulting in shorter processing times.
- You Only Look Once (YOLO). YOLO treats object detection as a regression problem and predicts bounding boxes and class probabilities directly from the entire image in a single pass.
- Single Shot Detector (SSD). SSD is similar to YOLO in that it predicts bounding boxes and class probabilities directly from the image in a single pass. Still, it uses multiple layers with different aspect ratios to detect objects at different scales.
- RetinaNet. This object detection algorithm uses a focal loss function to address the class imbalance problem in object detection, where negative examples greatly outweigh the positive ones.
- Mask R-CNN. This object detection algorithm extends Faster R-CNN to predict object masks, bounding boxes, and class probabilities.
These algorithms have different trade-offs in terms of speed, accuracy, and complexity, and the choice of algorithm depends on the specific application and requirements.
How does Google Lens work?

Google Lens is an image recognition technology developed by Google that allows users to use their smartphone cameras to search for information about objects in the real world. Here’s how Google Lens works:
- Image capture. The user takes a picture of an object using their smartphone camera.
- Image processing. The image is sent to Google’s servers, where it undergoes various processing steps, such as image recognition, object detection, and feature extraction.
- Object recognition. The image is analyzed to identify any objects or text within it using deep learning models, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs).
- Information retrieval. Once the object has been identified, Google Lens retrieves relevant information about it from various sources, such as Google Search, Google Maps, and Google Translate.
- Display results. The results are displayed to the user in a user-friendly format, such as a knowledge panel or a pop-up card, which may include information about the object’s history, related products, or nearby locations.
With Google Lens, people can translate, do smart text selection, smart text search, shop, ask Google questions, search around them, and much more.
Technical aspects of Google Lens
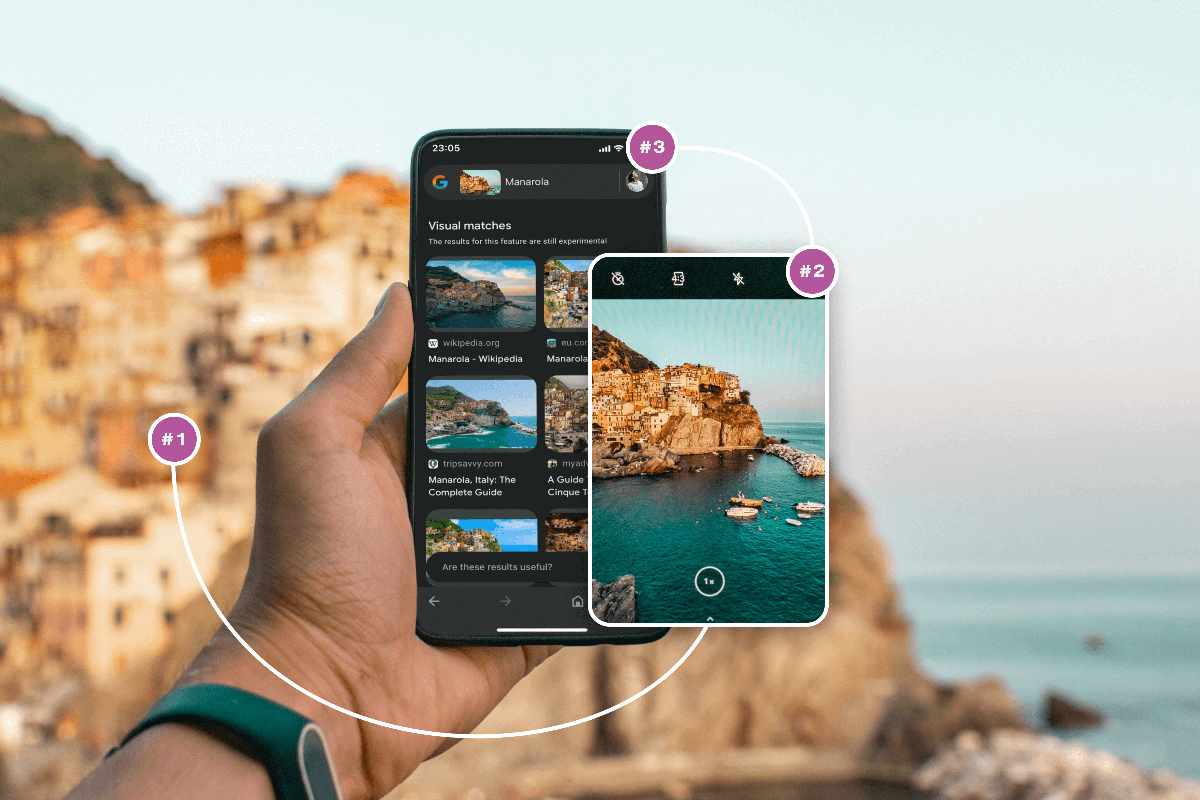
Here are some technical aspects of Google Lens:
- Deep learning models. Google Lens uses deep learning models like CNNs and RNNs to perform object and text recognition. These models are trained on massive amounts of data to learn to recognize objects and text in various contexts.
- Cloud-based processing. Google Lens relies on cloud-based processing to perform image processing and object recognition, which allows it to leverage Google’s massive computing infrastructure and scale seamlessly.
- Integration with other Google services. Google Lens is integrated with other services, such as Google Search, Google Maps, and Google Translate, to retrieve relevant information about identified objects and provide a seamless user experience.
- Real-time processing. Google Lens is designed to work in real-time, allowing users to get instant results from their smartphone cameras. This requires high-performance computing and efficient algorithms to minimize the processing time.
Overall, Google Lens is an advanced image recognition technology that uses deep learning models and cloud-based processing to identify objects and text in real-time and retrieve relevant information from various sources.
Examples of image recognition apps
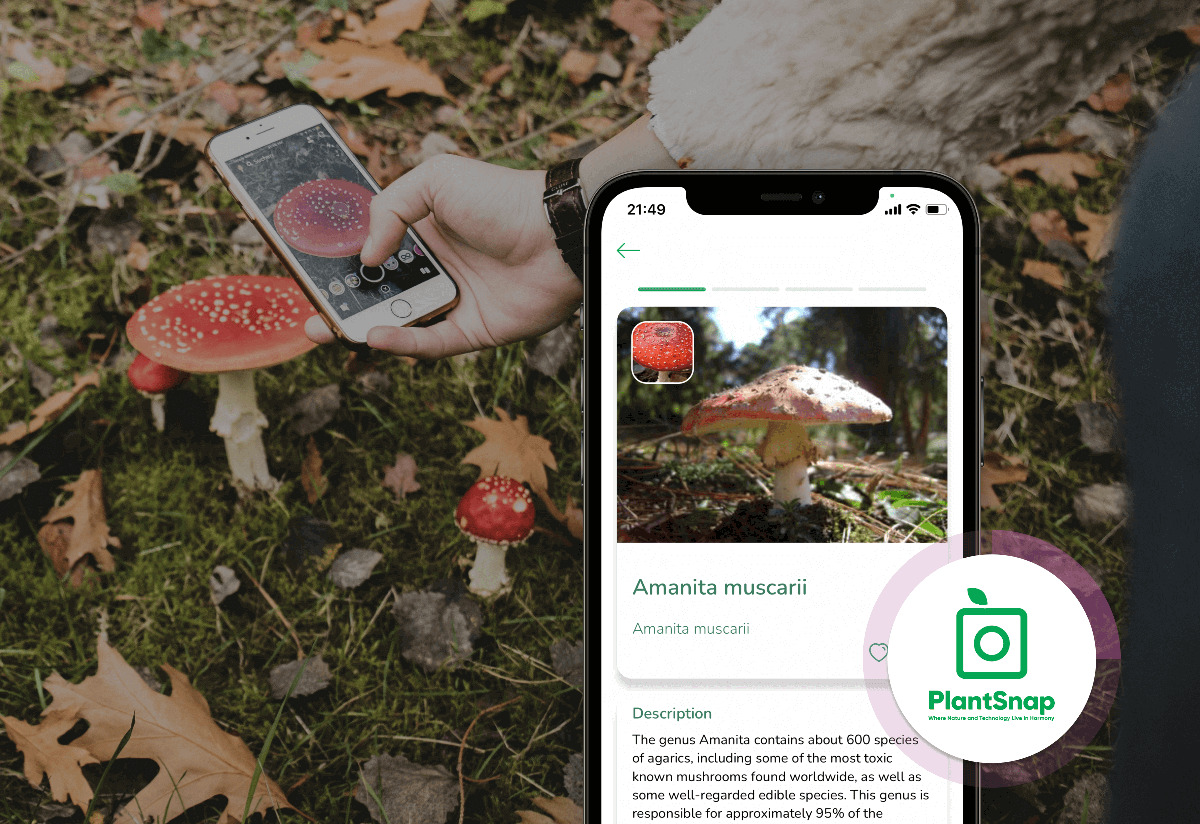
Image recognition technology has many practical applications, and many apps use it to improve user experiences:
- Shazam. This app identifies songs by listening to music and matching them with a known song database.
- Snapchat. It uses image recognition to apply filters and effects to users’ faces, such as adding dog ears or a flower crown.
- Amazon Go. It is a cashierless store that uses image recognition to track customers’ movements and purchases in real-time.
- Ikea Place. Thanks to image recognition technology, this app allows users to place virtual furniture in their homes to see how it would look before making a purchase.
- PlantSnap. It identifies plants and flowers in real-time, allowing users to learn more about them.
- Vivino. It identifies wine labels and provides information about the wine, such as reviews, ratings, and pricing.
These are just a few examples of today’s many image recognition apps. As technology continues to improve, we can expect to see even more innovative apps that use image recognition to enhance our lives in new and exciting ways.
How to develop an image recognition app?

Developing an image recognition app is a complex process. Here are the main steps:
- Defining the app’s purpose and features. Before starting development, it’s essential to determine the app’s purpose and characteristics. This includes identifying the types of objects or images the app will recognize, the level of accuracy required, and any additional features, such as real-time processing or integration with other services.
- Collecting and preprocessing data. This step is needed to train the ML models to power image recognition. This involves collecting a large dataset of images and annotating them with labels that indicate the objects or features of interest. The images may also need to be preprocessed to improve their quality or standardize their format.
- Training ML models. Once the dataset is collected and preprocessed, the next step is to train machine learning models using techniques such as convolutional neural networks (CNNs) or recurrent neural networks (RNNs). The models should be trained on a subset of the data and validated on another subset to ensure they accurately identify the objects or features of interest.
- Developing and testing the app. Now it is necessary to integrate ML models into the app and create UI and other features. The app should be thoroughly tested to ensure accuracy, responsiveness, and usability.
- Deploying and monitoring the app. After deploying an app to users, it’s vital to monitor its performance and accuracy and make improvements as needed.
Developing an image recognition app requires Python or Java developers and experience with ML frameworks such as TensorFlow or PyTorch. It also requires access to powerful computing resources to train the machine learning models. And the Soloway team can help you with this.
Working Together: An Inside Look at Our Collaboration Process

Choosing a reliable object detection development partner with case studies and niche expertise is challenging for many businesses. But you are lucky as you encountered the SoloWay team.
We are experts in object detection technology development with several successful projects in this domain. Our ability to scale quickly and establish processes allows you to start working on the project almost immediately. Over 14 years of technological expertise help us to deliver cutting-edge solutions to our clients. Our cooperation with you will look like this:
- Problem analysis. We start with an in-depth analysis to understand your business, requests, and current position in the market.
- Solution creation. We assemble a team and start with prototyping and UI/UX design.
- MVP development. We make your project live as an MVP using Agile methodology.
- Product integration. We release the product and help you integrate the solution into your tech infrastructure.
- Support and update. We can further support your project to keep your product running optimally.
We recently worked on a web-based search engine for an e-commerce shop. This project was reviewed by our project manager, Oksana Lysionok:
“We were able to address the low conversion issue by implementing changes to both the application and website’s UX. We stabilized the system and added new functionality that simplified the service for users. As the project is large and consists of many components, it has taught us to take a comprehensive approach to problem-solving”.
Our team for this project included: UX/UI designers, analysts, React Native and Python developers, QA experts, ReactJS/Node.js developers, and a project manager.
Final thoughts
A reliable partner in object detection technology development should have a team of experts who are knowledgeable and skilled in computer vision and machine learning. They should have a strong understanding of object detection techniques and the latest advancements in the field. And you already know one such partner – SoloWay.




